Performance of a Large Language Model in the Generation of Clinical Guidelines for Antibiotic Prophylaxis in Spine Surgery
Article information

Abstract
Objective
Large language models, such as chat generative pre-trained transformer (ChatGPT), have great potential for streamlining medical processes and assisting physicians in clinical decision-making. This study aimed to assess the potential of ChatGPT’s 2 models (GPT-3.5 and GPT-4.0) to support clinical decision-making by comparing its responses for antibiotic prophylaxis in spine surgery to accepted clinical guidelines.
Methods
ChatGPT models were prompted with questions from the North American Spine Society (NASS) Evidence-based Clinical Guidelines for Multidisciplinary Spine Care for Antibiotic Prophylaxis in Spine Surgery (2013). Its responses were then compared and assessed for accuracy.
Results
Of the 16 NASS guideline questions concerning antibiotic prophylaxis, 10 responses (62.5%) were accurate in ChatGPT’s GPT-3.5 model and 13 (81%) were accurate in GPT-4.0. Twenty-five percent of GPT-3.5 answers were deemed as overly confident while 62.5% of GPT-4.0 answers directly used the NASS guideline as evidence for its response.
Conclusion
ChatGPT demonstrated an impressive ability to accurately answer clinical questions. GPT-3.5 model’s performance was limited by its tendency to give overly confident responses and its inability to identify the most significant elements in its responses. GPT-4.0 model’s responses had higher accuracy and cited the NASS guideline as direct evidence many times. While GPT-4.0 is still far from perfect, it has shown an exceptional ability to extract the most relevant research available compared to GPT-3.5. Thus, while ChatGPT has shown far-reaching potential, scrutiny should still be exercised regarding its clinical use at this time.
INTRODUCTION
Chat generative pre-trained transformer (ChatGPT) is a 175 billion-parameter large language model (LLM) developed by OpenAI and trained on a large, nondomain specific corpus of textual data from the Internet [1]. Since ChatGPT’s public release in November 2022, the model has gained widespread attention for its “human-like” responses to textual prompts, including its apparent ability to show deductive reasoning skills, coherence, and continuity in its generated responses.
Artificial intelligence (AI) models have long been used in the medical field to assist in imaging analysis and provide clinical decision-making support. Recently, natural language processing (NLP) models have been applied to many medical tasks, including billing code generation [2,3], prediction of patient outcomes and mortality [4], and prediction of emergency hospital admissions [5]. NLP chatbots further have the potential to be applied in patient-facing primary care settings [6]. Researchers have begun investigating novel applications of ChatGPT for various medical tasks, such as the generation of accurate and clinically relevant medical information and guidance. Because the model is capable of passing the United States Medical Licensing Exam (USMLE) [7,8], some researchers have suggested that ChatGPT may assist in medical education and clinical decision-making.
To assess the potential of ChatGPT as a clinical decision-making support tool, it is imperative to assess not only whether ChatGPT can give accurate recommendations, but also if its reasoning aligns with established clinical guidelines that follow evidence-based practices. Generating clinical guidelines is a labor-intensive process that requires continuous updates; therefore, applying ChatGPT reliably in this area could prove beneficial to medical practitioners if it can accurately synthesize patient scenarios and provide relevant recommendations. One study found that ChatGPT could appropriately understand hypothetical patient infection scenarios and recognized complex management considerations, however, it failed to distinguish clinically important factors without prior prompting and sometimes failed to give appropriate management plans [9].
ChatGPT currently has 2 models available to the public: GPT-3.5 and GPT-4.0. GPT-4.0 is a more advanced system with a monthly subscription of $20, purported to be safer and more accurate than GPT-3.5, the free version, according to ChatGPT’s developer OpenAI [1]. In this study, we assess ChatGPT’s 2 models in their ability to generate accurate clinical guidelines on antibiotic prophylaxis in spine surgery using 16 questions from the North American Spine Society (NASS) Evidence-Based Clinical Guidelines for Multidisciplinary Spine Care.
MATERIALS AND METHODS
The NASS’s Evidence-Based Clinical Guidelines for Multidisciplinary Spine Care: Antibiotic Prophylaxis in Spine Surgery [10], revised in 2013, was used as the clinical standard. Two ChatGPT models, GPT-3.5 and GPT-4.0, were asked independently to answer each of the 16 clinical questions addressed in this guideline—an example is shown in Fig. 1. A new chat was created for each question to avoid biases from prior prompts. If the question did not include a reference to spine surgery, it was modified to include these words. Otherwise, the prompts were presented to the models exactly as they appeared in the NASS guidelines. Each response was recorded verbatim, summarized, and compared to the NASS guideline recommendations for accuracy. Acknowledging that GPT has a tendency to provide long-winded and sometimes repetitive information in its responses, the responses were summarized to the key recommendations, which were compared to the NASS recommendations to determine accuracy. In cases where NASS guidelines gave no recommendation due to insufficient evidence, we judged the GPT response correct if it was also able to conclude that no specific recommendation could be provided. Additionally, to account for potential outdated answers in the NASS guidelines, we searched the literature for studies published in the last ten years to discern if the NASS guidelines were still supported by recent research and determine if ChatGPT responses were unaligned with the NASS guidelines but aligned with more recent research.

Example response of ChatGPT’s prompt and response in the GPT-3.5 model. ChatGPT, chat generative pre-trained transformer.
An example of this process is shown in Fig. 2. This response was graded as accurate. ChatGPT produced the correct response that prophylactic antibiotics reduce surgical site infection (SSI) incidence and stated that studies have shown no difference in single-dose versus multiple-dose prophylaxis regimens in spine surgeries. This corresponds well with the NASS guideline recommendation that preoperative antibiotic prophylaxis has shown decreased infection rates.

An example flowchart of the question and compare process. We posed the North American Spine Society Clinical Guidelines question to ChatGPT (GPT-3.5 and GPT-4.0), recorded its response verbatim, then summarized it for brevity. This summary was then compared to the guideline recommendations. ChatGPT, chat generative pre-trained transformer.
Responses for both the GPT-3.5 and GPT-4.0 were evaluated for accuracy compared to the NASS guidelines, and the performance of the 2 models were compared. To further assess the advancement from GPT-3.5 to 4.0, we additionally evaluated 2 aspects of GPT-4.0’s advancements that have been highlighted by the OpenAI team: a decrease in overconfidence, which was defined as when the model would support statements that had conflicting data in the literature and guidelines without referencing the ambiguity in the literature, and a more advanced capability to provide real citations. Thus, we assessed GPT-3.5’s tendency for overconfidence in its responses as well as GPT-4.0’s ability to reference the NASS guidelines.
RESULTS
1. Question Content
Sixteen questions in the NASS guidelines addressed the use of antibiotic prophylaxis in open spine surgery. Four of these regarded the efficacy of antibiotic prophylaxis in preventing infections in open spine surgery; 4 others are concerned with protocols for selection, intraoperative, and postoperative application of antibiotic prophylaxis; 1 is on redosing; 2 are on discontinuation; 3 discuss the effects of comorbidities and body habitus; and 2 are on complications arising from antibiotic prophylaxis. Six of the total questions posed binary responses, while the 10 remaining contained more complex responses.
2. Overall Performance
Comparing ChatGPT’s GPT-3.5 model with the NASS clinical guideline recommendations, 10 responses (62.5%) were accurate and 6 (37.5%) were inaccurate. The model adequately answered all questions related to antibiotic redosing, wound drains, body habitus and comorbidities. It was inaccurate for 1 of 4 questions on antibiotic efficacy, 3 of 4 questions on antibiotic protocol, 1 of 1 question on antibiotic discontinuation, and 1 of 2 questions on antibiotic complications. Compared to the NASS clinical guideline recommendations, ChatGPT’s GPT-4.0 model correctly answered 13 responses (81%) and inaccurately answered 3 (19%). The more advanced model answered all questions related to antibiotic efficacy, redosing, wound drains, body habitus and complications. It inaccurately answered 1 of 4 questions on antibiotic protocol, 1 of 1 question on antibiotic discontinuation, and 1 of 2 questions on antibiotic comorbidities (Tables 1, 2; Fig. 3).
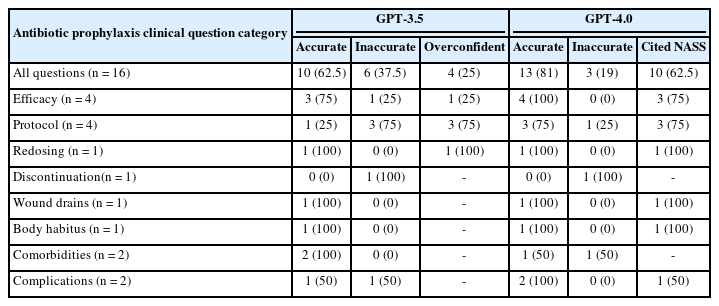
ChatGPT’s performance (GPT-3.5 & GPT-4.0) compared to the North American Spine Society (NASS) clinical guidelines for clinical questions relating to antibiotic prophylaxis in spine surgery, broken down by question category

A comparison of the clinical questions and North American Spine Society (NASS) guidelines for antibiotics prophylaxis in spine surgery with corresponding ChatGPT model recommendations (GPT-3.5 & GPT-4.0)

Breakdown in GPT-3.5 and GPT-4.0 model performance by subtopic. GPT, generative pre-trained transformer.
DISCUSSION
1. Efficacy
Three of 4 efficacy questions were binary questions concerned the efficacy of antibiotics in preventing SSIs in general open spine surgery, spine surgery with implants, and spine surgery without implants. Both ChatGPT models adequately answered that antibiotic prophylaxis decreases the rate of SSIs in all 3 cases, with GPT-4.0 even citing the NASS guidelines as evidence for its responses. Studies have shown a positive effect of antibiotic prophylaxis on reducing SSIs in general spine surgery as well as instrumented and non-instrumented spine surgery [11-13] which aligns with NASS guidelines.
The last question concerned the expected rate of SSIs when antibiotic prophylaxis is applied. The NASS guidelines report an infection rate of 0.7%–10% while a recent meta-analysis reported an infection rate of 3.1% in all spine surgeries with prophylaxis [14]. GPT-3.5 failed to report a prevalence of SSIs, instead falsely citing that the incidence of SSIs is lowered by 60%–80% with antibiotic prophylaxis use. Additionally, the guidelines report that patients with diabetes face an increased risk of SSIs, but there was insufficient evidence to definitively state whether obesity increased the risk of SSIs. GPT-3.5 correctly identified the relationship between SSI risk and diabetes but not for obesity [15], overconfidently stating that obesity increases risk for SSI despite insufficient evidence to support this point. While some recent studies have reported an impact of obesity on SSIs [16,17], others have suggested that comorbidities often seen in obese patients, such as diabetes, may be the ultimate driver of increased SSI rates [18], while others suggest that body habitus, rather than obesity, affects SSI rate [19]. In comparison, GPT-4.0 correctly answered this question and refrained from making incorrect assumptions by conveying the ambiguity of this topic.
2. Protocol
Three of 4 protocol questions concerned the recommended drugs, dosages, administration routes, and timing for general spine surgery and spine surgery with or without implants. The clinical guidelines state that the superiority of any drug, dose, or route of administration has not been demonstrated, and since the release of these guidelines, the literature has yet to determine a superior protocol for general spine surgery [20,21]. While several studies have investigated varying prophylaxis protocols, the evidence remains contradictory and insufficient to merit a recommendation [20]. In response to these questions, GPT-3.5 failed to definitively state that no single drug, dosage, or administration route was recommended while GPT-4.0 accurately answered all three. For 2 questions, GPT-3.5 explicitly stated that cefazolin was the recommended first-line antibiotic, but this is inconclusive in the literature.
The last question asked for a reasonable algorithmic approach to antibiotic selection for a given patient. The clinical guidelines recommend one single preoperative dose of the antibiotic of choice, with intraoperative redosing as needed, for simple and uncomplicated spinal procedures with consideration of additional gram-negative coverage and/or the application of intrawound vancomycin or gentamicin for complicated cases. Both ChatGPT models gave a general list of steps that could be taken to choose appropriate antibiotics and protocols rather than the correct recommendations outlined for simple and complex procedures.
3. Redosing and Discontinuation
One question asked about intraoperative redosing and drug recommendations. To the best of our knowledge, there have been no studies directly examining the effects of redosing on SSI incidence, but many studies that have included intraoperative redosing protocols in their cohorts agree with a standard redosing protocol within 3 to 4 hours of the initial dose [22,23], in line with NASS guidelines. The guidelines also state that the superiority of one drug has not been definitively established. ChatGPT models gave individual redosing recommendations for several common antibiotics and recommended redosing after 3–4 hours for cefazolin, which we rated as accurate.
Another question asked whether discontinuation of antibiotic prophylaxis after 24 hours had an effect on SSI incidence compared to a longer duration. ChatGPT correctly answered that discontinuation at 24 hours does not increase SSI risk compared to longer durations, which has been reported by several studies [13,20,24,25]. While ChatGPT models are not accurate compared to the outdated guidelines from 2013, they are both accurate in their answers.
4. Wound Drains and Body Habitus
One question asked if discontinuation of antibiotic prophylaxis at 24 hours affected incidence of SSIs compared to discontinuation at the time of wound drain removal. At the time of the release of the NASS guidelines, few studies had examined the effect of prophylaxis discontinuation with wound drains, resulting in insufficient evidence to make a recommendation [26,27]. Since the release of the guidelines, ambiguity remains in the literature, although one study has shown that discontinuing antibiotics at the time of drain removal does not decrease the rate of SSIs [28]. ChatGPT correctly stated that no recommendation could be made.
Another question asked if the recommended prophylaxis protocol differs based on body habitus or body mass index. While the literature has shown that obese patients may face higher risks of SSIs following posterior cervical spine surgery [29] and lumbar spine surgery [30], there is currently no consensus on alternative antibiotic prophylaxis protocols for obese patients. ChatGPT adequately conveyed that the evidence is too limited to suggest an altered antibiotic regimen based on body habitus.
5. Comorbidities
Two questions addressed comorbidities associated with antibiotic prophylaxis. One asked if comorbidities other than obesity necessitate altered antibiotic prophylaxis protocols. According to the NASS guidelines, surgeons should consider altered protocols for patients with various comorbidities; for example, diabetic patients may benefit from intraoperative redosing [31], and the intrawound application of vancomycin has been reported to significantly decrease the incidence of deep and superficial SSIs in patients with comorbidities [32]. ChatGPT adequately responded that there are several alternative protocols that have been shown to help prevent SSIs in patients with various comorbidities, with GPT-4.0 directly citing the NASS guideline.
A second question asked if vancomycin reduces infections by methicillin-resistant Staphylococcus aureus (MRSA) in patients with a history of MRSA infection. At the time of the release of the guidelines, there was insufficient evidence to make a recommendation. While a recent meta-analysis has suggested that local application of vancomycin powder can reduce the incidence of MRSA infections following posterior spine surgery [33] and elective lumbar procedures [34], other studies have reported no impact of vancomycin on SSI or gram-negative infection incidence [35,36]. Therefore, the evidence remains insufficient to make a recommendation. GPT-3.5 was correct in that it did not give a recommendation for an approach and stated the use of vancomycin for reducing MRSA infection should be based on patient risk factors, the local prevalence of MRSA, and institutional guidelines. Meanwhile, GPT-4.0 gave one study that suggested a quality improvement approach would decrease postoperative infections including MRSA and MSSA infections without reporting insufficient evidence, hence making this answer incorrect.
6. Complications
One question concerned the general incidence and severity of complications arising from the use of antibiotic prophylaxis in spine surgery. The reported incidence of antibiotics-related complications is low [12,37], although flushing, hypotension [38], and rash [39] have been reported in rare cases. Both ChatGPT models answered the question by listing several potential complications that were not directly listed in the guidelines.
A second question asked what strategies can be implemented to reduce the risk of complications related to the use of antibiotic prophylaxis. The NASS guidelines recommend a single dose of preoperative prophylactic antibiotics with intraoperative redosing as needed for uncomplicated spine procedures. GPT-3.5 provided a long list of general strategies, some of which were accurate and clinically relevant but others were incomplete, overgeneralized and contradictory. For example, it recommended that the duration of prophylaxis be limited to the perioperative period, stating prolonged prophylaxis is known to result in increased risk of adverse events and infections; however, in the discontinuation category, GPT-3.5 reported no difference in infections between perioperative and prolonged durations of prophylaxis, and in the comorbidities category, it suggested that prolonged duration of prophylaxis could help reduce SSI risk in patients with comorbidities. GPT-4.0 correctly answered this question by citing the NASS guidelines and pointing to its recommendations.
7. General Discussion
ChatGPT demonstrated an impressive ability to accurately answer clinical questions given that it was not specifically trained on a medical dataset. While both models showed good comprehension of the prompts, GPT-3.5 model’s performance was limited by its tendency to give overly confident responses for prompts with non-conclusive evidence and its inability to identify the most significant elements in its response. For example, in the protocol category, GPT-3.5 did not definitively state that there was not enough evidence to recommend a specific protocol, instead defaulting to a general statement that several factors should be considered. However, in other cases, it was able to convey lack of consensus on the given question in its response—for example, in the body habitus and comorbidities category. GPT-4.0 model’s responses not only had higher accuracy but also cited the NASS guideline as direct evidence in 10 of the 16 questions it correctly answered. This points to its exceptional ability to extract the most relevant research available compared to GPT-3.5 in its recommendation for antibiotic prophylaxis in spine surgery.
It is not surprising that GPT-4.0 outperformed GPT-3.5. The newer model was trained on a larger and more recent dataset than its predecessor, although the details of this data set and training process have not been released to the public. Additionally, human reviewers and AI were used to provide reinforcement learning for GPT-4.0. These improvements have been shown to decrease GPT-4.0’s tendency to “hallucinate” responses compared to its predecessor and give up to 40% more factual information [1].
One of the most significant limitations to the application of ChatGPT in clinical settings is the unpredictability of the model’s responses. ChatGPT is programmed to give plausible-sounding responses, but the actual information contained in the response may be incorrect, misleading, or completely fabricated, especially in the widely available and free GPT-3.5 model. We found GPT-3.5 was overconfident in 4 of 16 questions (25%), sometimes fabricating studies and citing nonexistent papers to prove its point. However, while several responses containing fabricated references were ultimately correct, the information could not be easily confirmed. A significant obstacle facing ChatGPT and other LLMs is their inclination to provide conclusive responses even if it would be more accurate to indicate a lack of agreement. This has been labeled artificial hallucination, where LLMs tend to produce plausible statements without any real basis in their training data [40].
GPT-4.0 is a more enhanced model that ameliorates this effect by including direct citations to its sources, with 10 of 16 questions (62.5%) ultimately citing the NASS guideline to back up its correct answers. However, another obstacle facing ChatGPT in clinical settings that has been noted by other researchers is its inconsistency. Howard et al. [9] reported that the clinical recommendations provided by ChatGPT often changed on repeated questioning. While we did not prompt ChatGPT the same questions multiple times, we did observe minor inconsistencies in its responses, namely its shifting recommendations for prolonged duration of prophylaxis.
GPT should be used with proper care and caution in clinical settings. GPT-4.0’s ability to cite literature has the potential to be used by clinicians for consolidating disparate sources of information and summarizing them. Even still, it is not always accurate and should be further validated when being used to guide important clinical decision-making.
8. Future Directions
Development of next generation LLMs is already underway with the future release of GPT-4.0 Turbo [1], which in addition to providing more complex responses to textual prompts allows for pretraining and domain specific models such as those trained on medical literature. Other medical domain specific models such as Med-PaLM are in development, but do not have public access yet. The excitement around these models and their potential widespread applications must be counterbalanced by sufficient research investigating the limitations and potential hazards of applying this technology in clinical settings. The application of LLMs in complex clinical settings can present serious ethical issues for both patient care and concerning liability. There is the possibility for LLMs to give inaccurate responses, particularly when prompted for medical advice given the imbalance of medical information in the training data. These responses must be aligned with clinical knowledge. In cases where a discrepancy exists and patients are affected, the question of liability and minimizing patient harm is of ethical importance. Future research should continue to assess the performance of LLMs, including the latest version of ChatGPT, in order to provide medical professionals with evidence-based guidelines for the use of LLMs. Furthermore, these assessments could benefit from deeper investigations into prompt engineering, which is the process of structuring prompts in order to optimize the comprehension of the LLM. Small changes in the structure of prompts could lead to potentially major discrepancies in responses, which present additional challenges to the application of LLMs in clinical settings that must be addressed. Real-world clinical applications of these models include responding to common patient questions and automated analysis of medical records. However, there are still challenges such as ensuring proper data privacy and accuracy of responses.
9. Limitations
A limitation of this study is that the NASS Evidence-Based Clinical Guidelines for Multidisciplinary Spinal Care have not been updated since 2013 and may now be outdated, while ChatGPT has been trained on textual data from the Internet up to 2021. However, this source represents the most recent organizational guidelines for spinal prophylaxis. We also compared ChatGPT’s responses to the most up-to-date literature, with GPT-3.5 trained with data up to 2021 and GPT-4.0 to April 2023 [1], therefore, more recent literature may not be entirely reflected in its responses. Another limitation of this study is that LLMs may not always respond identically to a given prompt, and are often updated making comparisons between responses more difficult. Moreover, this study is limited by the prompts that were used as they were verbatim from the guidelines and subject to the biases inherent in their structuring and phrasing. Given the nature of AI, advances happen rapidly and newer models are currently being developed which may perform better or be trained on more clinically focused data. Finally, the training data used on the models has never been publicly stated, and as such there may be biases and gaps in medical knowledge that are not publicly known.
CONCLUSION
This study suggests that we continue to approach LLMs with caution and optimism. While GPT-3.5 was able to generate clinically relevant antibiotic use guidelines for spinal surgery, its inability to identify the most important aspects of the comparable guidelines and its redundancy, fabrication of citations, and inconsistency are obstacles to the application of the model in clinical settings. At the same time, GPT-4.0 was almost 20% better in its response accuracy and was able to cite the NASS guideline 62.5% of the time. While ChatGPT has far-reaching potential in directing users to evidence-based research as a basis of its findings, scrutiny should still be exercised in using ChatGPT reliably at this time. Medical practitioners should be cautioned against relying on ChatGPT for clinical recommendations on antibiotic prophylaxis in spine surgery without close scrutiny of the medical literature.
Notes
Conflict of Interest
Jun S. Kim: Stryker, Paid consultant. Samuel Kang-Wook Cho, FAAOS: AAOS, Board or committee member; American Orthopaedic Association, Board or committee member; AOSpine North America, Board or committee member; Cervical Spine Research Society, Board or committee member; Globus Medical, IP royalties; North American Spine Society, Board or committee member; Scoliosis Research Society, Board or committee member; Stryker, Paid consultant. The following authors have nothing to disclose: Bashar Zaidat, Nancy Shrestha, Wasil Ahmed, Rami Rajjoub, Ashley M. Rosenberg, Timothy Hoang, Mateo Restrepo Mejia, Akiro H. Duey, Justin E. Tang.
Funding/Support
This study received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author Contribution
Conceptualization: BZ, SKC; Formal Analysis: BZ; Investigation: BZ; Methodology: BZ; Project Administration: BZ, JSK, SKC; Writing - Original Draft: BZ, NS, AMR; Writing - Review & Editing: BZ, NS, AMR, WA, RR, TH, MRM, AHD, JET, JSK, SKC.