INTRODUCTION
Computed tomography (CT) imaging is an essential modality in the diagnosis of neurosurgical disease [1-3]. In spine surgery, is routinely employed to assess the extent of injury or signs of degeneration [1,4]. Furthermore, CT imaging plays a vital role in surgical intervention planning for spinal tumors, degenerative as well as infectious spinal diseases, and can be required for establishing a precise neuronavigation setup [5,6].
Despite advances in radiation technology, patients remain exposed to significant doses of ionizing radiation. While the average annual background radiation in the United States is estimated at approximately 3 mSv, the radiation exposure for a lumbar spine CT scan are much lower, typically around 1.5 mSv [7]. However, in cases of polytrauma, extensive examination is indicated so that radiation doses can exceed 20 mSv [8].
Patients with severe spinal cord injuries may also be hemodynamically unstable and require immobilization, making CT imaging challenging [9,10]. Moreover, due to financial constraints, many centers worldwide have limited access to this specialized modality [11]. To maintain full operational capability, radiographers and radiologists are necessary, further adding to the financial burden.
Generating 3-dimensional (3D) information from a 2-dimensional (2D) input has the potential to assist in addressing these issues. The feasibility of creating synthetic, CT-like 3D imaging using deep learning from biplanar chest x-ray images has been demonstrated [12]. A similar machine learning based application for spine imaging, however, is currently missing. In this proof-of-concept study, the main objective was to assess the feasibility of creating synthetic spinal CT images using deep learning by using biplanar digitally reconstructed radiographs (DRRs) as inputs, serving as a proxy for true biplanar x-ray images.
MATERIALS AND METHODS
1. Overview
Noncontrast enhanced spinal CT scans from 209 patients and their DRRs, sourced from the VerSe2020 dataset, were used for model development [13-15]. The VerSe20 dataset also includes manually refined segmentations of the vertebrae. To generate 2D-to-3D synthetic CT (sCT) images, a generative adversarial network (GAN) model was trained on these images, following the methodology previously established by Ying et al. [12]. Model evaluation was subsequently carried out on 55 cases from the VerSe20 dataset [13-15] (internal validation) and a randomly selected subset of 56 patients from the CTSpine1K dataset [16] (external validation) using structural similarity index (SSIM), peak signal to noise ratio (PSNR), and cosine similarity (CS) as metrics.
2. Ethical Considerations
The VerSe20 and CTSpine1K datasets are publicly available and ethical approval has been obtained by the original publishers from the corresponding ethics committees.
3. Data Sources
The CT data used for model development and evaluation originated from multiple centers and was obtained from the VerSe2020 dataset. This publicly available dataset includes spinal imaging from cervical, thoracic and lumbar regions acquired on scanners from multiple manufacturers and features a variety of pathologies, such as vertebral fractures, deformities, and implants [13-15]. For external validation a randomly selected subset of 56 images originating from the MSD-T10 and COVID-19 datasets, which are both part of the CTSpine1K dataset [16], was applied. Some further information on the datasets is provided in Table 1.
Given the necessity for corresponding radiographs to the CT scans, in this feasibility study, DRRs were derived—serving as a proxy for true biplanar x-rays. They were generated from the 3D-CT scans using the Plastimatch software [17], which offers relatively high fidelity to actual x-ray images, making them an ideal basis for model training. However, it is important to note that DRRs are not exact replicas of conventional x-rays. In order to highlight bone structures, Hounsfield units (HU) windowing was applied with a window center of 400 HU and a window width of 1,300 HU. In addition, the vertebrae segmentations were employed to extract the bones. The pelvis and sacrum were excluded from consideration.
4. Metrics
For assessment of model performance, 3 evaluation metrics were employed: PSNR, SSIM, and CS. PSNR serves as a widely accepted quantitative metric for determining the fidelity of reconstructed digital signals, with higher values indicating superior image quality [18]. SSIM provides a multifaceted assessment of image similarity by considering factors like luminance, contrast, and structure [18,19]. Unlike metrics such as mean squared error and PSNR that focus on absolute errors only, SSIM is designed to correspond more closely with human perception of image quality. Finally, CS is a can be applied to measure similarity by assessing the cosine of the angle between 2 feature vectors [20]. Results for both SSIM and CS range from -1 (completely dissimilar) to 1 (identical). As PSNR values depend on the bit depth of the image, there is no fixed definition of a good score [18].
SSIM is calculated once for all 3 dimensions and averaged thereafter. In order to calculate CS images were flattened into a 1-dimensional vector.
5. Model Development and Validation
All CT scans were resampled to achieve a uniform voxel spacing of 1× 1× 1 mm³ and the image dimensions were standardized to 256× 256× 256 pixels. Thereafter, biplanar DRRs were derived for all CT scans. These DRRs acted as the input for both training and assessing our GAN model. The CT images were then windowed, and the spinal structures extracted as described before. Finally, the total number of unique grayscale values was compressed to 100, while maintaining the integrity of the overall data distribution. This was accomplished through the development of a lookup table, which enabled a systematic mapping of HU to their corresponding bins (quantization).
A GAN was fine-tuned on the training set, allowing us to create sCTs from biplanar DRRs. The basic model architecture was adapted from X2CT-GAN [12], and certain parameters were adjusted to meet the specific requirements of our task. The final model underwent 100 epochs of training with a learning rate of 0.00005. Final evaluation was carried out on the 2 holdout sets to assess PSNR, SSIM, and CS. The sCTs were generated to have a resolution of 192× 192× 192 voxels. Fig. 1 schematically depicts the data extraction, model application and evaluation process. All calculations were performed with Python 3.10.6 and PyTorch 1.12.1 for CUDA 11.6.
RESULTS
2. Model Performance
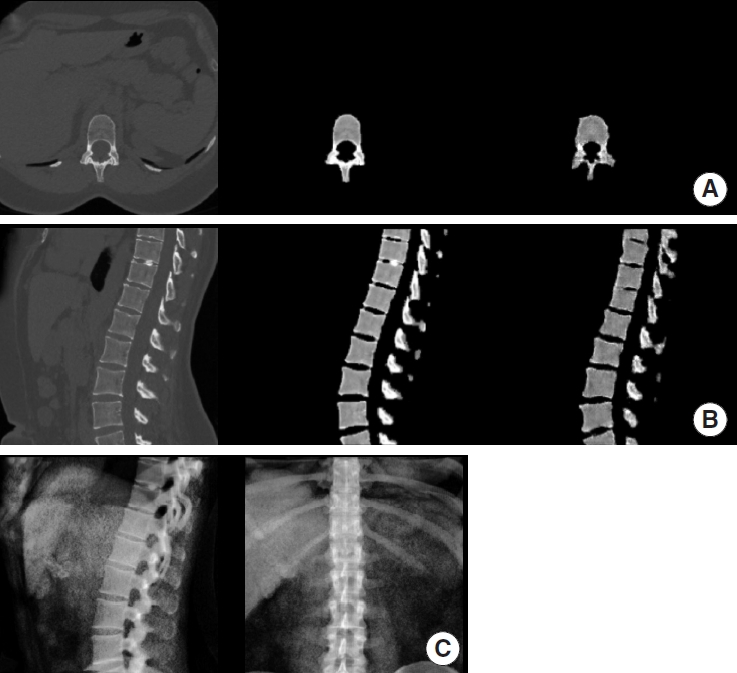
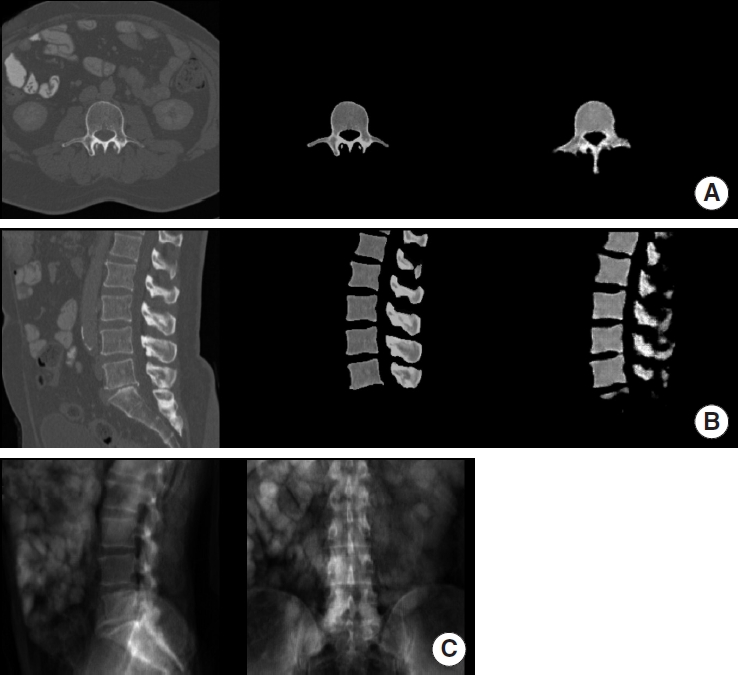
Table 2 outlines model performance. A visual comparison between synthetic images generated by our GAN and the corresponding ground truth data is depicted in Fig. 2 for a case taken from the internal validation and Fig. 3 from the external validation set.
Fig. 4 depicts a comparison in 3D space of the synthetically generated spinal column derived from DRRs and the ground truth version obtained through manual segmentation.
DISCUSSION
Utilizing a multicenter dataset encompassing over 300 patients, a 2D-to-3D GAN capable of synthesizing spinal CT images from biplanar radiographs was successfully developed and externally evaluated. In terms of performance, the model yielded promising but not fully satisfying results, revealing that while the sCT are not able to completely replace traditional CT scans, they might offer a viable alternative in certain clinical settings.
The generation of sCT images from x-rays holds promise for reducing time, cost, and radiation exposure associated with CT scans. Unlike CT, radiographic imaging has major limitations to performing 3D anatomical evaluations. This study proposes a model capable of generating sCTs using DRRs as input. While these synthetically generated images may not match the quality of actual CT scans in every respect, it is possible that a more advanced version of the model, trained on a larger dataset, at higher resolution and on real radiographs instead of DRRs, could provide sufficient diagnostic information to make a real CT redundant in specific scenarios. The aim should not be to replace CTs as a whole, but much rather extend the current applications of radiography machines. We believe that by using x-rays from 2 planes (anterior-posterior and lateral), it should be possible to obtain enough depth information to generate reliable, 3D images using deep learning. The depth information and consequently the quality of our synthetic imaging will absolutely be limited compared to authentic CTs. Such an application, however, would for example be very beneficial in low resource settings, where CTs are not accessible but x-ray machines are.
Apart from reducing radiation exposure and improving economic efficiency, our model could also directly influence patient treatment. For instance, fluoroscopy machines are commonly used in neurosurgical operating theatres for spinal surgeries. By using such fluoroscopic imaging as input, 3D imaging could be generated, thus enhancing orientation and decreasing spatial awareness problems during surgery.
The model training approach we used necessitates manual vertebrae segmentation. We discovered that omitting the bone extraction leads to less uniform results in the generated sCTs. This lack in performance is likely due to the variable characteristics of the surrounding soft tissue, which appeared to interfere with the model’s ability to learn appropriately. Such a manual approach dramatically increases the training time and introduces the potential for human error. Additional work, on a new automated deep-learning segmentation model to streamline the training process is ongoing. However, it needs to be reiterated, that although the model has been trained semiautomatically, its application on new data is already fully automated, as all that is required for the generation of the sCT are the biplanar radiographs/DRRs.
Quantization was employed in order to reduce the number of individual grayscale images in our CTs while retaining as much of the overall data distribution as possible. This significantly decreases computational costs of model training with the drawback of losing the exact Hounsfield intensities and loosing image depth. The exact number of gray shades a human eye can discern is debated, however medical displays typically offer 8 bits or 256 shades of gray [21]. In such scenarios, the benefits of higher-depth imaging can only be taken advantage of by adjusting contrast and brightness. By using a binning approach with 100 bins (grayscale units), our method remains below this threshold. However, we plan to explore expanding the grayscale range in the future.
It is important to exercise caution when interpreting CS as a measure for image similarity. While PSNR and SSIM are established metrics for image fidelity assessment, to the best of our knowledge, there is no literature available that investigates CS’s utility for this purpose. CS is a commonly used similarity measure applied to text documents, for example for clustering [22]. As, based on our personal observation, this metric corresponded relatively well with our subjective qualitative assessment of the synthetic imaging, we decided on including it in our evaluation anyway.
Our model performance in terms of SSIM appear quite high, reaching 0.947 at external validation. However, it is important to note that, as we remove all the soft tissue from our imaging, a substantial part of our synthetic and ground truth CTs is made up of background. As SSIM is calculated over the entire image and the spinal column only constitutes a comparably small fraction of the overall volume, the model easily reconstructs the background which results in a high SSIM score.
There have been multiple approaches aimed at generating higher-dimensional images from single-plane radiographs [23,24]. However, these approaches lack depth information due to their reliance on a single view so that the generated images may not offer the accuracy needed for precise diagnostic or surgical planning. In contrast, deep-learning approaches using multiplane radiographs as input in order to create CT-like imaging have been successful [12,25]. Furthermore, several previous studies describe spine-specific methodologies to extrapolate 3D information from biplanar, 2D radiographic imaging [26-33]. Most of these studies employed statistical approaches, while only a smaller subset has leveraged machine learning. Notably, instead of generating CT-like imaging, all these investigations focused on generating 3D models of the spine. To the best of our knowledge, only one previous study attempted to apply a GAN in a similar fashion for generating synthetic, CT-like spinal images from biplanar DRRs [34]. Saravi et al. [34], who independently performed their study in parallel to ours, used DRRs generated after extraction of the vertebrae for the generation of the sCTs, while we derived the DRRs before extraction. Therefore, the DRRs used to train our model are more similar to authentic x-rays. The major next step towards clinical applicability, however, will be applying this technique to real x-rays or fluoroscopy images, instead of DRRs.
To translate a model like the one we propose into clinical practice, several steps are required. First, the model needs to be thoroughly evaluated in silico. To achieve this, it needs to be trained on more data originating from as many centers as possible, while additionally increasing data variability by applying data augmentation methods. Future research should also assess the performance of the model separately for axial and sagittal 2D image slices. These 2 planes are of especially high diagnostic relevance and axial imaging can only be reconstructed indirectly when using anterior-posterior and lateral x-rays as input, presumably making it more error-prone. Furthermore, future studies need to perform a more accurate assessment by using real radiograph images as input instead of DDRs. Once this has been established, clinical trials to assess the model’s utility in clinical practice are necessary. This could be accomplished by comparing authentic CT scans to the synthetic imaging for specific inquiries such as implant placement after spinal fusion surgery or more general diagnostic questions. Only after conducting clinical trials can the true clinical utility of a model, like the one we propose, really be understood.
Even though the developed model was trained on a rather large and diverse training dataset, encompassing 209 spinal images that spanned the lumbar, thoracic, and cervical regions, more data is likely to improve its performance. This is particularly relevant for spinal imaging as it can exhibit significant variability between individuals.
Notably, cervical imaging was underrepresented in the training and evaluation data, and model performance based on spinal region needs to be evaluated in future studies. Similarly, the impact of surgical implants on our model’s performance has not been assessed yet.
Although established image quality metrics (PSNR, SSIM, and CS) were employed, these measurements probably do not capture the full clinical utility of the generated sCTs. For a detailed understanding of the model’s applicability, additional clinically relevant metrics need to be included in combination with an expert radiological evaluation.
In this proof-of-concept study, we managed to successfully externally validate our model. However, to ensure adequate generalizability, validation on data from further centers is would be beneficial.
Lastly, DRRs were used as training input as a substitute for real x-rays, being an initial proof-of-concept study. DRRs offer high fidelity and serve as a useful approximation but they cannot fully replace conventional x-rays. One of the major challenges we faced in using real x-rays is the lack of correspondence of x-rays to CTs in terms of orientation and relative size. Frequently, the x-ray beam is not perpendicular to the skull, and the distance from the x-ray source can also vary. It is thus essential for future research to explore methods that allow for the use of authentic x-rays as model input.
CONCLUSION
We present a proof-of-concept study of TomoRay, a GAN targeted at generating synthetic CT scans of the cervical, thoracic, and lumbar spine from biplanar imaging. While the quality of our algorithm-generated CT scans has not yet reached the level of authentic CT scans, our study warrants further exploration of the potential of this technology.